I encountered this issue while creating an application that used Amazon S3 as its storage solution. This was a strange one.
Issue Description
So... I was trying to leverage DynamoDB's non-expiring free-tier limit to store and retrieve text data. But the problem with DynamoDB is, 1 "write capacity" only allows creating/writing rows (items) with the maximum size of 1KB. I wanted to use as fewer write capacities as possible for my application. So, I decided to store just the metadata in DynamoDB and the actual large chunk of texts in S3. The plan was to use Amazon Lambda to retrieve metadata from DynamoDB and use those metadata to retrieve needed text data from S3. I decided to store text data in *.txt format as it is universal.
I created several text files using Notepad and uploaded them to an intended directory inside my S3 bucket. The texts inside the .txt files were perfectly legible when I created them and when I uploaded them to S3 (I could open those files in S3 console and see that they were fine). But, as I retrieved the text using {s3Client}.getObject, the text had some strange characters. I noticed some characters such as quotes(') being replaced by random strings like "\uffd". I scoured through the internet to find the solution. I found some, such as :
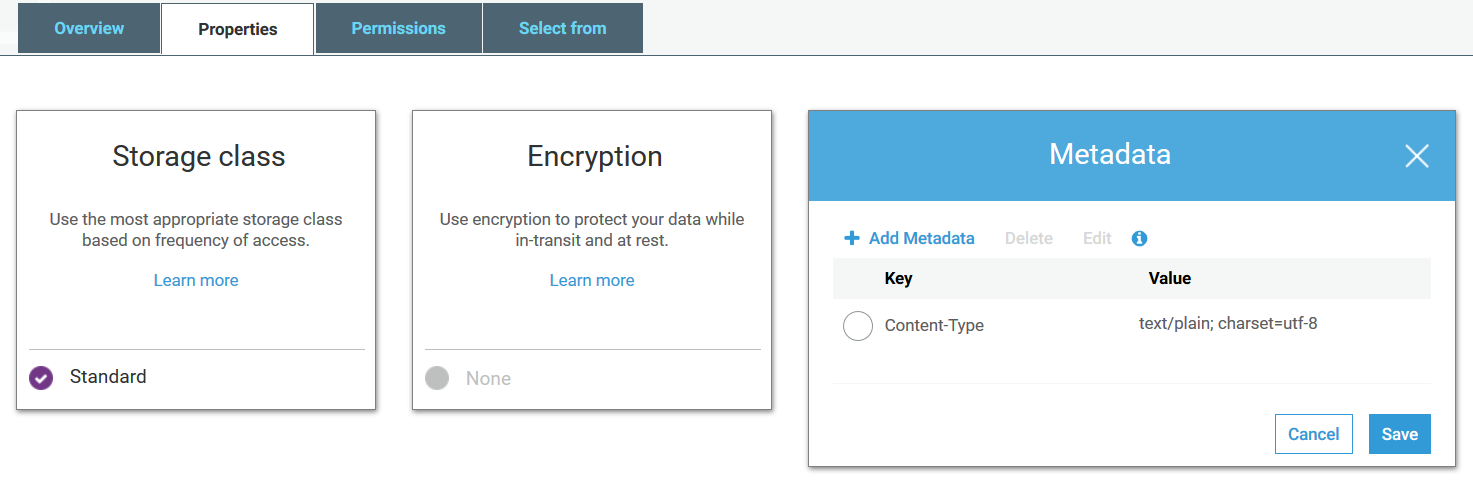
Adding metadata "Content-Type": "text/plain; charset=utf-8" to the uploaded file.
Giving "utf-8" parameter to the text-body-parsing function.
s3Client.getObject(s3Params, function(err, content){ if(err){ callback(err, null); } else { data = content.Body.toString("utf-8"); callback(null, data); } });
These are definitely some helpful tips but they didn't help on their own in my case.
Solution
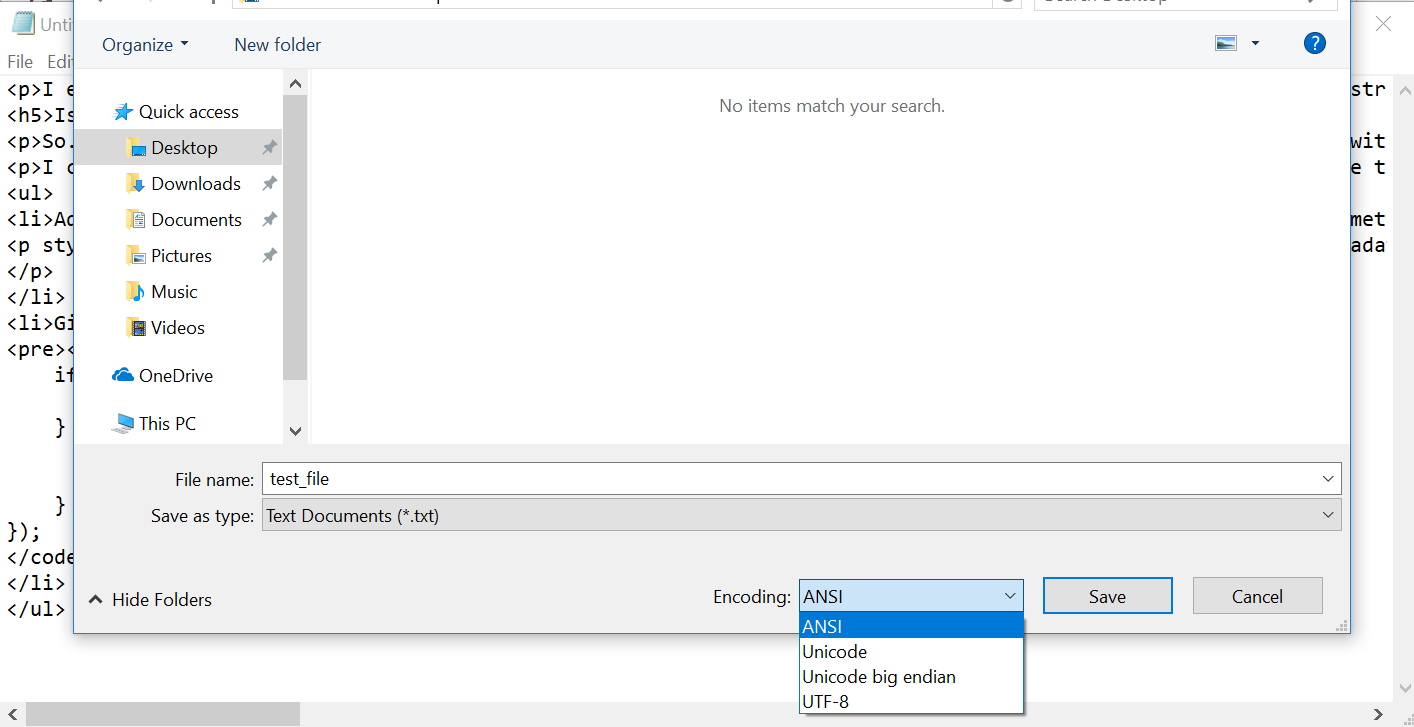
In the end, the solution was extremely simple. As it turned out, my .txt files were in ANSI format. All I had to do was re-save all those .txt files in "UTF-8" format. Windows Notepad gives us that option. Also, while uploading those files onto S3, I had to set their metadata to be "Content-Type": "text/plain; charset=utf-8" as shown above.